Why You Scraped 1,000 Instagram Profiles and Got 50 Emails
Learn why your email yield is low and how to diagnose match rate issues. A practical guide to niche email density, eligibility rate, and coverage optimization.
On this page (28 sections)
(Match Rate, Niche Email Density and How to Fix Your Yield without "Scraping More")
You've done an Instagram scrape, got a shiny list of 1 000 profiles out of it and felt like you'd hit the jackpot.
Then you opened the file.
50 emails.
Not 300. Not 500. Fifty.
If that's you, here's the uncomfortable truth: this result is often completely normal - and it usually has nothing to do with how "good" the scraper you're using is.
The number that you are interested in isn't "profiles scraped." It's email yield, and yield is constrained by two forces:
- Niche email density -- how often people in your niche share email in public
- Match rate -- how efficiently you use your workflow to convert "eligible profiles" into extracted emails
This guide provides you with a practical repeatable way to diagnose where your yield is leaking from, calculate realistic expectations, and increase yield by changing the inputs that matter (not by mindlessly scraping more).
TL;DR (If You Want the Short Answer)
Getting 50 emails from 1,000 Instagram profiles can be anticipated when:
- A large percentage of profiles are not eligible (private, inactive, repost pages, personal accounts, no bio, duplicates)
- Your niche has low email density (people like using DMs, don't display email in public, link-in-bio)
- The emails that are out there are not in plain text (obfuscated formatting) or are not found in places that your workflow doesn't capture
- You're not separating extracted e-mails from valid e-mails (verification reduces usable results)
The fix usually isn't "scrape 10,000."
It's: select a higher density niche, improve eligibility and measure your yield ceiling before scaling.
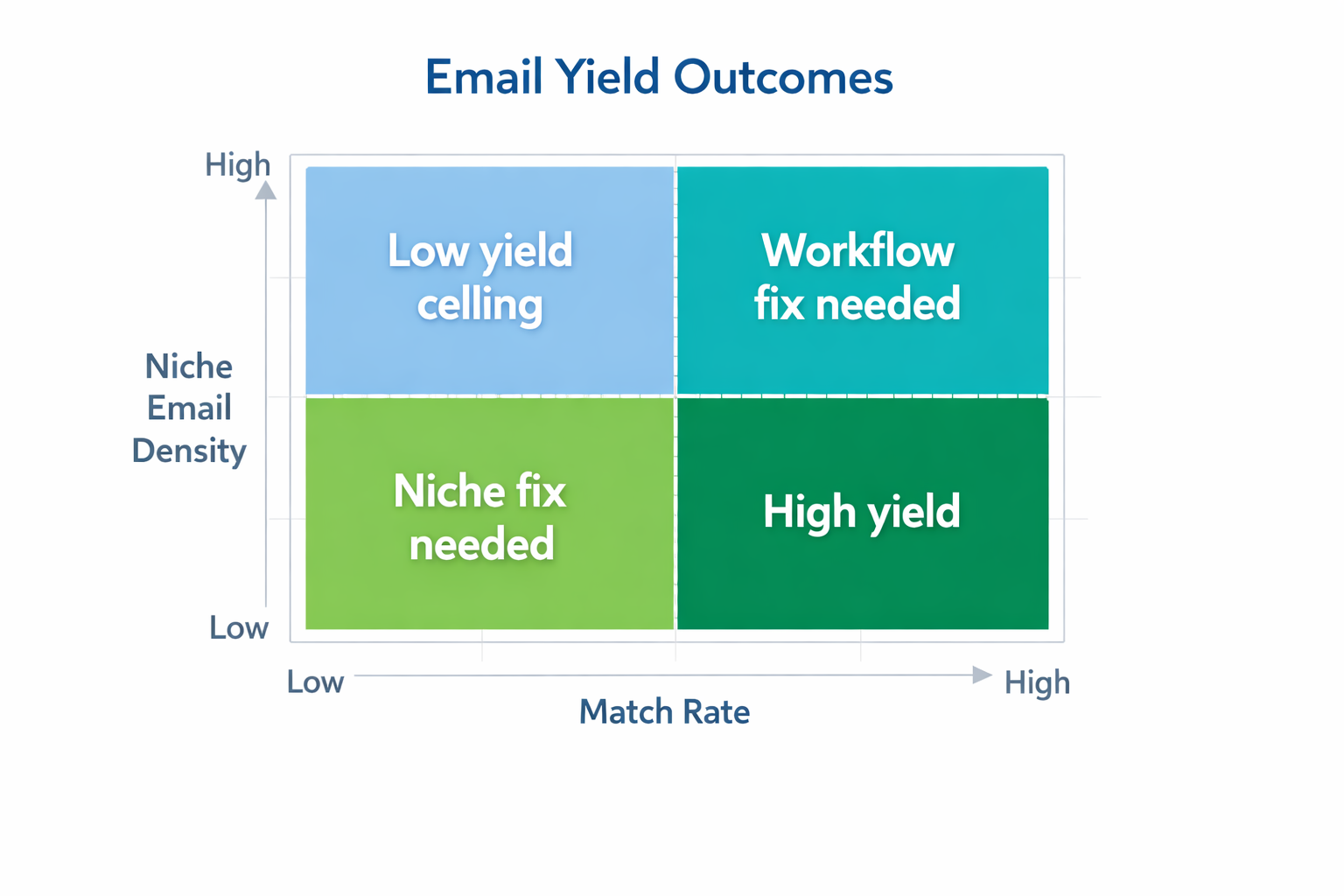
Two Concepts That Can Explain Almost Everything
Niche Email Density
Niche email density is the percentage of profiles in a niche which display an email address in public (in bio or other public contact surfaces).
Different niches behave in different ways:
- Creators / influencers often say "DM for collabs" - density of email contacts is usually lower
- Local services (studios, clinics, agencies) often want bookings - density of emails is often higher
- Ecommerce brands may route contact through a website link - email may exist, but not on Instagram itself
Email density is your natural supply. A tool can't make what a niche doesn't make public.
Match Rate
Match rate is the effectiveness of your process in pulling emails out of the profiles where emails might reasonably be found.
Match rate is approximately your workflow quality, i.e., filtering, parsing, de-duplication, enrichment strategy and verification.
Key idea:
Scraped profiles ≠ eligible profiles.
You can scrape 1,000 profiles and have only 600-800 profiles that are even "eligible" to produce an email.
Email Yield Funnel (Why it's Normal for 1,000 - 50)
Most everyone assumes that the funnel is:
Scrape profiles → Get emails
But the actual funnel looks like this:
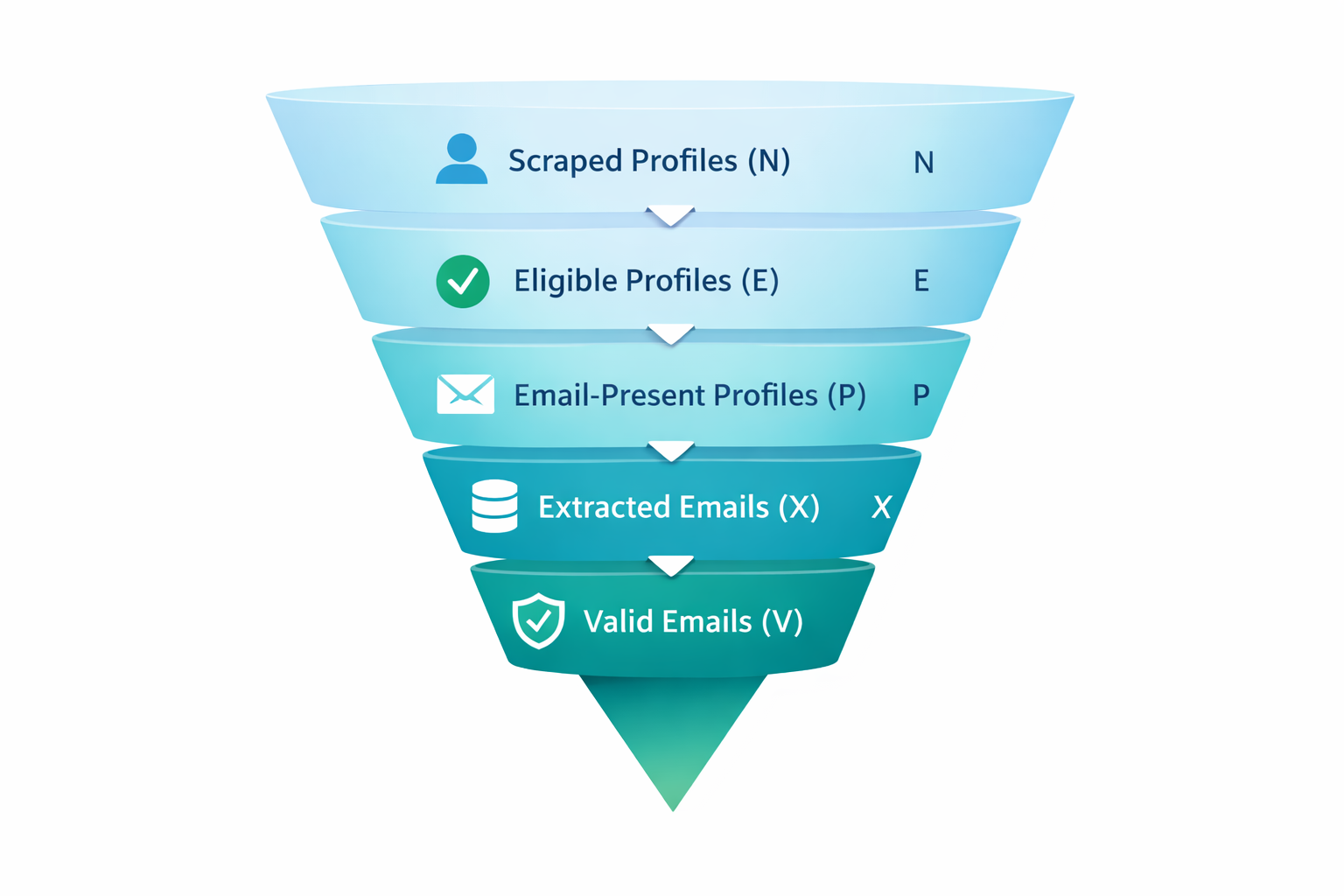
Scraped profiles (N)
Eligible profiles (E) Not private/ not dead / not duplicates / within your ICP
Email-present profiles (P) Profiles that actually show an email publicly somewhere you are able to capture
Extracted emails (X) Emails that were parsed into your output successfully
Valid emails (V) Emails that pass verification and are safe to contact
Thus the realistic question is:
"How many of my profiles are eligible, how dense is the email in this niche and what's my extraction coverage?"
The Practical Formula (To Use Before Scaling)
Extracted emails (X) ≈ E x (density of niche email) x (coverage)
Valid emails (V) ≈ X x (validity rate)
The following is a credible scenario that hits smack-dab at 50:
- N = 1,000 scraped profiles
- E = 800 eligible profiles (20% out of profiles: private, irrelevant, duplicates, no bio)
- Niche email density = 8% (only 8% of the profiles eligible for email show email publicly)
- Coverage = 80% (workflow covers 80% of those emails)
- X ≈ 800 x 0.08 x 0.80 = 51.2 emails
That's your "50 emails."
Not a failure. A math problem.
The Usefulness Of Mental Models (Yield Ceiling)
Think of niche email density as your yield ceiling.
If your niche only has 3-8% email density, then your "best possible outcome" may be 30-80 emails/1000 eligible profiles - even with a perfect workflow.
This is why "scrape more" often leads to disappointment: you are scaling a low-yield niche.
The 15-Minute Audit: Locate Your Yield Leakage
Don't guess. Audit.

Step 1: Randomly Sample 50 Profiles
From your scraped list, choose 50 profiles at random and label them manually in a very simple sheet.
Recommended columns:
- Private? (Y/N)
- Bio present? (Y/N)
- Obviously a business/creator in your ICP? (Y/N)
- Email visible as plain text? (Y/N)
- Only website/ link in bio exists? (Y/N)
- "DM for..." language? (Y/N)
- Repost/fan page vibe? (Y/N)
- Duplicate brand/account? (Y/N)
Step 2: Determine These 3 Numbers
Eligibility Rate = E / N How many profiles are even worth a try?
Observed Email Density = P / E In your niche, out of those eligible profiles, how many profiles actually display an email?
Coverage Gap How many of the profiles in which you can view an email manually did your workflow extract?
That lets you know what exactly to fix:
- Low eligibility rate → your targeting/source strategy is wrong
- Low email density → your niche is DM-first/email is off-platform
- Big coverage gap → workflow/tool settings/parsing problem
Step 3: Decision Making in 5 Minutes
Use these rules:
- Density < 5%: Stop scaling. Change niche or change profile sourcing.
- Density 5-15% but extraction is low: fix coverage and workflow before scraping more.
- Density high but valid emails low: verification/deliverability issue, not scraping
Common Causes of Getting 50 Emails: 9 Real Reasons (Grouped by Root Cause)
Group A: Your Niche Simply Doesn't Publish Emails (Low density of Emails)
1) DM-First Niches
Symptom: Bios are saying "DM for collabs," "DM for pricing," "DM to order."
What's happening, however, is that email is being avoided intentionally in order to reduce spam.
Fix: Move to niches which have "contact intent" (booking, quotes, B2B services).
2) Email Is off Platform (Website Link is the Gateway)
Symptom: Bio has a link, but no email.
What's going on: Lots of businesses will use a website contact form or "link-in-bio" page.
Fix: Workflow: Treat "has website link" as a quality lead signal, figuring out that you will (or will not) do ethical enrichment (more on this later).
3) Your Results Are Dominated by Non Business Accounts
Symptom: Meme pages, post pages, personal diaries, fan pages.
What's happening: Hashtag scraping tends to attract not the sellers, but content publishers.
Fix: Switch the origin of profiles (keywords that suggest transactions, location / service searches, indications of category)
Group B: Your List Contains a Low "Eligible Profile" Rate (Bad Inputs)
4) Your Scrape Source Doesn't Match to Your ICP
If you were to scrape followers of celebrity accounts, you would end up with consumers, not leads.
Scrape broad hashtags and you'll have creators, not businesses.
Fix: Source profiles of people who are actively offering something:
- service providers
- agencies
- studios
- B2B operators
- local businesses that have booking behavior
5) Too Many Private/ Inactive / Low Signal Accounts
Symptom: High number of profiles with no bio, no link, with a low activity.
Fix: Filter aggressively:
- bio present
- link present
- category/business cues
- recent posts (if that is in your data set)
6) You're Seeing Duplicates as "New Profiles"
Symptom: The existence of multiple profiles for the same brand; scraping of the same thing from multiple, overlapping profiles.
Fix: De-duplicate by:
- username
- brand name in bio
- domain in link
- extracted email
Duplicates can silently tear down your "emails per 1,000" metric.
Group C: Emails Exist, But your Workflow Doesn't Capture it (Coverage Issue)
7) Obfuscated Emails
People write:
- name (at) domain (dot) com
- name [at] domain . com
Fix: Use a normalization step that is aware of common obfuscation formats (or mark up these profiles for manual review). Even the slightest rate of obfuscation can lead to a drastic decrease in extraction in spam-sensitive niches.
8) Different Account Types Present Contact Info Differently
Some profiles exhibit contact details in various public surfaces depending on set-up.
Fix: Make sure that your workflow is consistent in what it is extracting:
- plain-text bio emails
- public contact fields (if they are available to your workflow)
- linked domains (as separate field for downstream enrichment decisions)
9) Rate Limits/ Partial exports of data
Symptom: Lots of missing fields in output (bio empty, link missing): especially at high speed.
Fix: Operational adjustments:
- reduce concurrency/speed
- run smaller batches
- log errors and compare output completeness from one run to the next
How to Have More Email Yields Without "Scraping More"
Lever 1: Increase the Email Density by Changing the Way You Source Profiles

Instead of asking the question "what hashtag should I scrape?", you should ask:
"Where do people indicate the intent to make contact?"
Look for cues of contact intentions and transactions
Examples of high signal words:
- "booking"
- "inquiries"
- "press"
- "wholesale"
- "quote"
- "appointments"
- "agency"
- "studio"
- "services"
- "available for"
You're not collecting accounts - you're collecting business behavior.
Practical tactic:
Build your lead list from searches that suggest that someone wants to be contacted professionally, rather than socially.
Lever 2: Improve Eligibility Rate Using a "Business Signal Filter"
Prior to actually extracting anything, classify profiles into:
- High signal Business Profiles: clear offer, CTA, Booking, Pricing Cues
- Medium-signal: link present offer unclear
- Low-signal - entertainment, repost, personal diary
If you're out and about doing outreach, you want a list which does something like:
"requests," "orders," "quotes," "appointments," "availability"
not
"memes", "fanpage", "daily life", "repost"
This one change can help you double your usable yield without having to change your tool.
Lever 3: Enhance Coverage Using a Simple Data Hygiene Pipeline
Even if you are not an engineer, you can implement the following basic steps:
- Normalize Emails Lower case, trim, remove trailing punctuation
- Separate extracted email email-like text TAG uncertain patterns for review
- De-duplicate from email + domain + brand cues
- Keep "website/domain" as a first class field (it's a lead quality signal even if it doesn't have an email)
Lever 4: Validate Before You Outreach (Your "Usable Email" Count is Important)
A list of 50 extracted emails is not equivalent to 50 usable emails.
Verification helps to safeguard your sender reputation and minimize wasted sends.
Best practice:
- verify first
- segment role based emails (info, hello, @) separately
- be careful when treating catch-all domains
- favor business domains over freemail when quality is an important consideration
Three Mini-Scenarios (So You Can Properly Benchmark)
These aren't any sort of "industry averages." They're examples to calibrate your thinking.
Scenario A: Services (Studios, Clinics, Agencies) located locally
- Frequently want bookings or quotes
- Email is commonplace or the business website is prominent
- Increased density, increased eligibility if made sourced correctly
- Best sourcing approach is as follows: service keywords + location cues + booking language.
Scenario B: The Creators / Influencers
- Collaboration is often DM-first
- Email may exist, but often reserved for larger creators or one that is managed by agencies
- Less density. More noise from fan pages/reposts
- Best move: segment by "management/agency/contact" cues and settle on a lower yield ceiling.
Scenario C: Small Brands in E-Commerce
- Email may be on website, not instagram
- Link-in-bio is common
- Density can appear to be low if you only try to extract bio emails
- Best move is to consider "has domain + clear product category" as the lead and then make the decision on ethical enrichment and verification.
A Simple "Yield Forecast" Worksheet (Use This Before Running Huge Jobs)
Before you scrape 10,000 profiles, predict your likely output:
- Run a 100-profile test scrape
- Measure eligibility rate (E/N)
- Take measurement of the observed email density (P/E)
- Compare manual visible emails vs extracted emails to get an idea of the coverage
- Multiply out
If you can't get acceptable results on 100 profiles, you won't magically be able to do so on 10,000 profiles -
you'll just spend more time getting disappointed at scale.
Compliance and Trust: How to Do This Responsibly (Read This).
This article is about improving yield and targeting quality - not going around the protections on platforms and encouraging spam.
If you're gathering publicly available contact information for reaching out:
- Respect the rules of the platforms and the local laws.
- Collect data minimum - gather what you need
- Be up front in outreach (what you are and why you are reaching out).
- Always have an easy opt out and honour them as fast as possible.
- Avoid mass blasting. Personalization and relevance help to protect the recipient as well as your sender reputation.
If you are not aware of the legal requirements in your jurisdiction (GDPR/UK GDPR, CAN-SPAM, PECR, etc.) then this should be taken as a matter of operation, and seek guidance from qualified counsel.
Where Scravio belongs This Workflow (Without the Hype)
If you have a true niche in publishing (bio/contact surfaces) for the emails, an Instagram email extraction workflow could work well - but only after you fix the inputs:
- source profiles with intent to make contact
- raise eligibility rate
- measure niche email density not in scale
- maintain domains/links for enrichment decisions downstream
- verify before outreach
If right now you're looking at "50 emails per 1,000 profiles" then don't go around blaming the tool.
Start by measuring:
- eligibility
- density
- coverage
That's how you make a rather disappointing export predictable.
Scravio supports multiple extraction methods:
- Followers - Extract emails from competitor or niche audiences
- Hashtags - Find businesses posting under commercial hashtags
- Likers - Target users who engaged with specific content
- Commenters - Reach the highest-intent audience
Learn more about finding contact-ready profiles and where Instagram business emails actually live in our related guides.
Final Takeaway
There is nothing secretive in your email result. It's a yield equation.
When you scrape 1000 profiles and only get 50 emails, this is usually reality one of these:
- your niche doesn't publish email.
- your list isn't eligible
- your workflow is not capturing what exists
- your verification step is cutting the list of usable down
Fix the right lever, and your output is predictable - often without having to increase the volume of scrape a bit.
Ready to improve your email yield? Scravio extracts emails from Instagram profiles with built-in verification and deduplication.
Try Scravio Free